Same story, different ending
Git Branching Model: A Journey Toward Perfection
All roads lead to Rome but, inevitably, adjustments must be made along the way to reach perfection.

The Application Development (AD) Project was successfully delivered to a Tier2 African Telecom Operator. It was a project led by choices but, most of all, by continuous learnings.
This article aims at sharing what were the major pains and what has sustained the decision to change from one branching model to another. In the end, you will find some precious clues for this kind of journey. But, please, don’t go straight to the end without putting yourselves in the team’s shoes. The goal isn’t to make any judgment on which model is better and which one you should use in your project, but rather to guide you to be better prepared to take that decision by yourselves – or at least that’s our hope.
First things first
When the AD team started the project, git versioning system was just in the beginning. Everything was almost new and only a few people were used to this tool. Previously, the project was structured in a way that it didn’t have to deal with partial releases, or, even worst, with some blocked requirements on the Testing environment, because they weren’t delivered with expectations of regular deployments into Production at the end of the two-week sprints.
As you might expect, this is a big deal to manage and the team soon started to become aware of it. To give it a go, the first choice was the so-called “GitFlow” model.
Our first choice – GitFlow
This flow promotes the existence of 2 main branches: a “master” branch, where the Production version of the code is saved and where the release numbers are managed; and a “develop” branch, where all new developments are committed and pushed. Then, you can use some supporting branches like “feature”, “hotfixes” and “release” that could be of great help, especially when you want to prepare, maintain and record releases, making sure that you don’t leave any important piece of code behind.
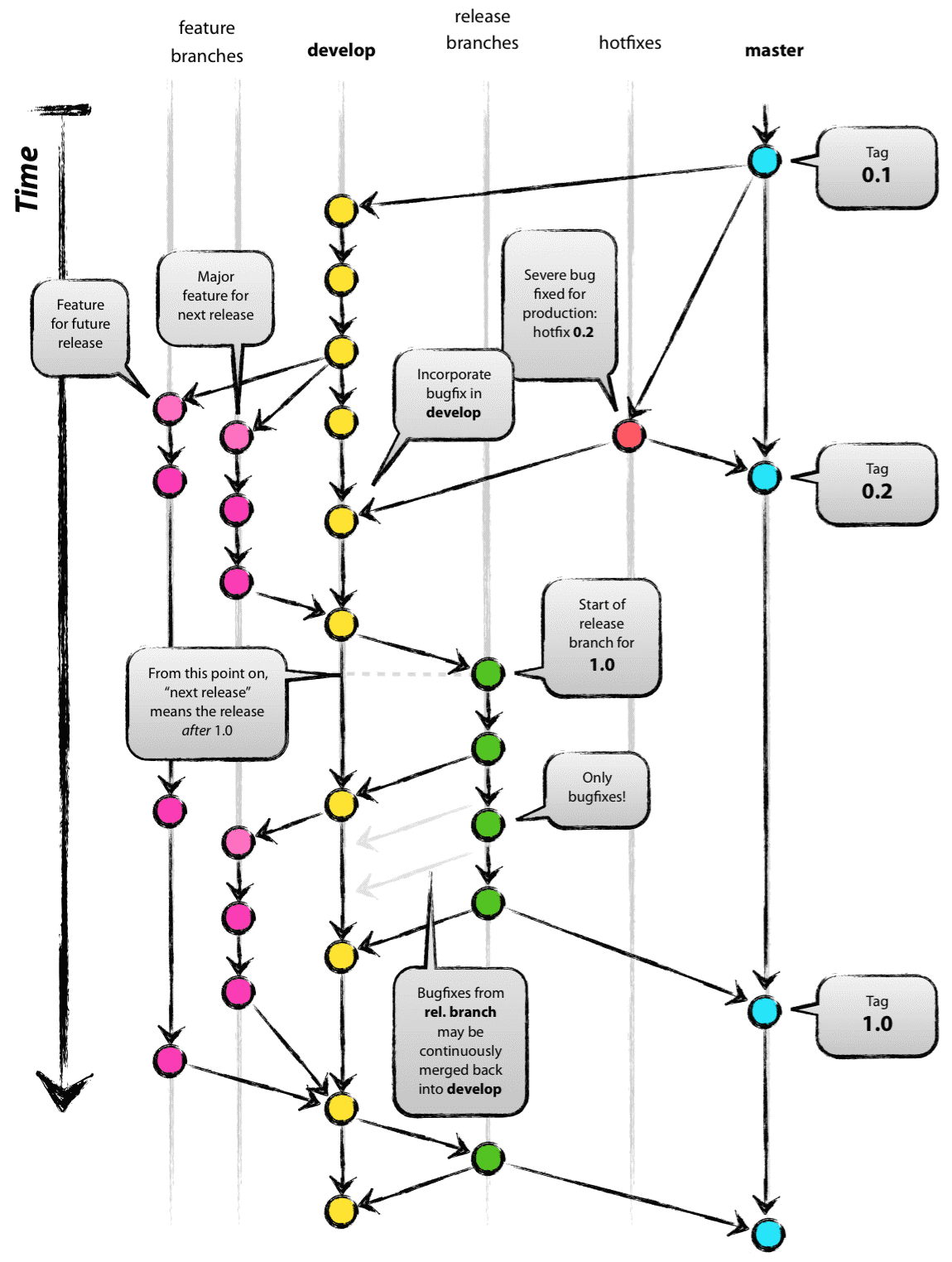
Figure 1 – A Successful Git Branching Model [1]
The main vision of this branching model is that a “master” is created and then, taking it as a baseline, the “develop” branch is initially formed.
All features (“feature” branches) are established using the “develop” branch as a baseline and, when features are done, they are merged back to be developed. Besides, all hotfixes are conceived using the “master” branch as a baseline and must be merged back to “master” when the fix is done - those changes must be merged simultaneously to “develop”.
When a release is about to be prepared, a “release” branch should be created using the HEAD of “develop” as a baseline. Some bug fixing could be made over this kind of branch, but when the fix is done, it must be incorporated back on the “develop”.
Finally, when the release is ok, a merge to “master” is done and a Tag version is built. At this time, the branch is no longer needed, and it can be deleted.
One thing that is used a lot in our projects, and isn’t mentioned in this model, is the “env” (environment) branches. This kind of branch is used to keep a version of the code released on the environment like Testing or Staging environments.
To sum things up
All branches are derived from “master” (even “develop”), but the “develop” branch is, like “master”, an eternal branch, and it soon starts to look like a completely different branch. As a result, as the feature branches keep being raised from "develop", it’s just a matter of time until problems during merges occurred, which is a common issue.
What led the team to change the branching model was the fact that when two features are being tested, "A" and "B", the branch of "B" has been created from "develop", after "A" has been merged to “develop”, and the client only approves “B”. As “B” already has all the code of the “A” feature, the only option is to dive into a diff & merge's marathon.
OneFlow consists of having only one eternal branch - “master”. Comparing to the GitFlow model, our first choice discussed in Part 1, the direct difference immediately detected was the absence of the “develop” branch. This approach of one long-lived branch doesn’t mean that there aren’t other branches involved using it. OneFlow should not be used when the new product release is not based on the previous release, which is the same requirement in using GitFlow.
This workflow employs an eternal branch and, in this case, as it is a Git convention, the team opted to maintain the “master” name, which is the branch containing the code from Production.
In OneFlow, the features branches are conceived from the “master” branch and not from the “develop” branch, like in GitFlow:
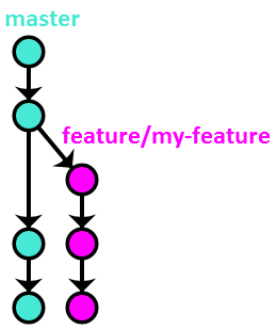
Figure 2 – Feature branches [2]
In our case, every feature was associated with a new requirement, allowing the developers to be more agile in the moment of the creation of a new release based on the approved requirements. Because multiple developers were working on the same requirement, each feature was pushed to the central repository.
For each production release, a new branch “release” was created. In this project, it meant producing a new branch from the “master” and merge each requirement (from the feature branch) to this new branch and tag it. Later, the “release” branch was merged to the “master”:
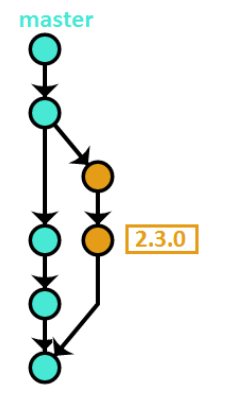
This release branch strategy is applied wherever a hotfix is needed to be applied – the difference is in the intent. A hotfix branch is an unwanted but necessary exception, typically because of some critical issues detected in the latest release.
In summary, the strategy for the OneFlow model was based on the delivery method for the Production release, which started with sprint releases but ended with selected requirements for each release.
Lessons learned
- Branches must be well isolated and maintained, the amount of work while merging can be reduced;
- The only code that is eternal is the one that is on the “master” branch;
- If this is all about code, both Application Development and Application Management teams should know and share responsibilities, while committing to the maintenance of a well-versioned code;
- One eternal branch only as a source of the truth is enough. The truth should be always what is versioned on the “master” branch. The other branches are a work-in-progress with an undetermined but expected end;
- Artefacts that are changed in an evolutive way shouldn’t be mixed with artefacts that are accessory, and nothing has to do with code evolution on the same repository.
Reference:
[1] https://nvie.com/posts/a-successful-git-branching-model/
[2] https://www.endoflineblog.com/oneflow-a-git-branching-model-and-workflow